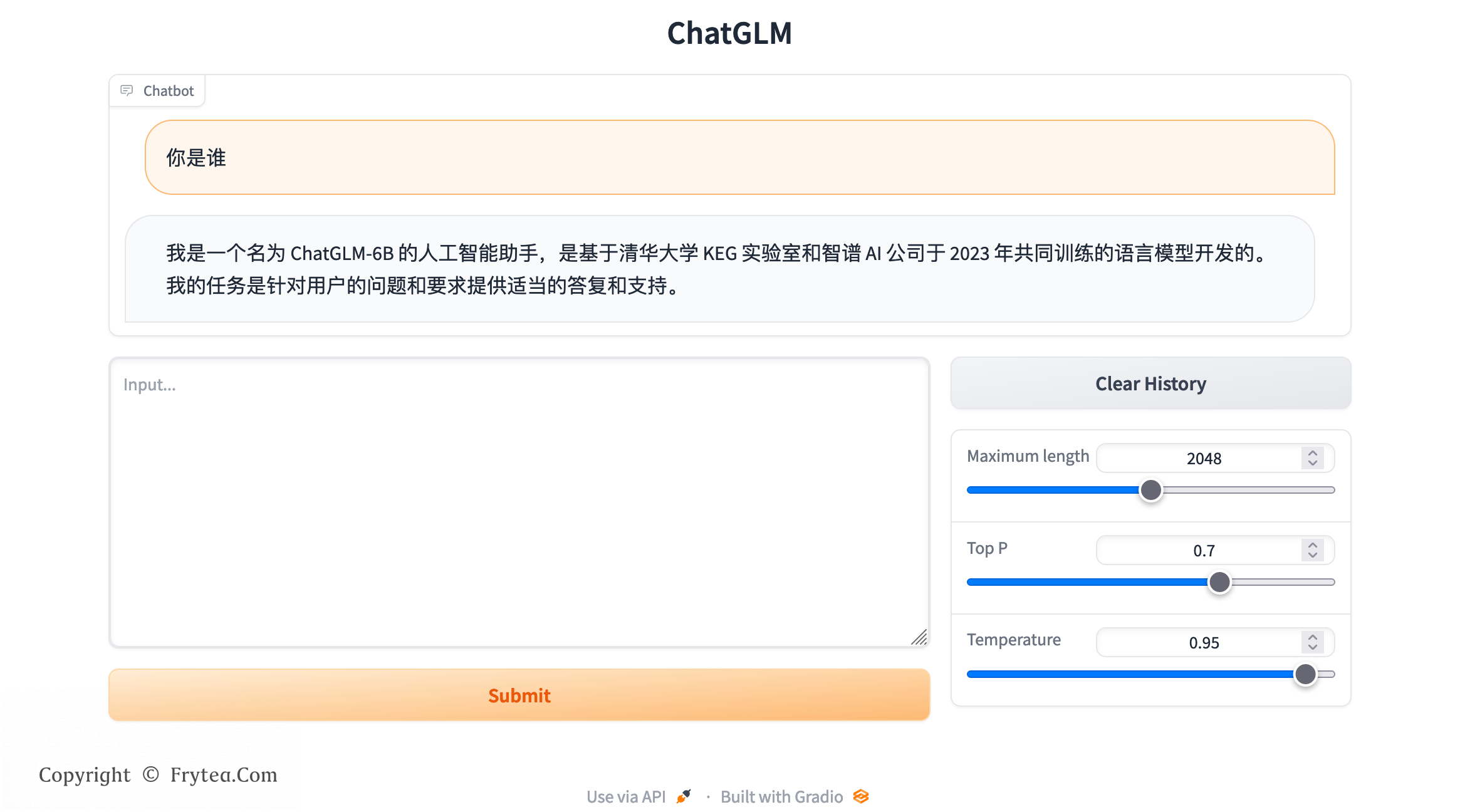
ChatGLM-6B 是一个由清华 THUDM 开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(
ChatGLM-6B 是一个由清华 THUDM 开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。

ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考他们的 博客。
我分别在以下平台做了测试:
- Macbook Air M1 8G
- VM - Debian 11 32C64G noGPU x86
其中 M1 平台下由于内存不足,只能够通过交换内存的方式艰难完成加载,在进行对话时会犹豫资源占用过高被杀。
在 Linux 虚拟机下可以正常运行和对话,但是速度稍慢,有 GPU 应该会快很多。

本文仅介绍在以上两种平台下的完整运行方法。
安装过程请全程自备加速器!
M1 MacOS 运行方法
在 M1 MacOS 下需要通过以下步骤配置安装,请按顺序进行。
环境安装
首先拉取代码仓库:
1 | # 拉取仓库 |
本地拉取模型
在 macOS 下运行必须手动拉取模型后本地加载,以下是本地模型拉取步骤。
从 Hugging Face Hub 下载模型需要先 安装 Git LFS,然后运行
1 | git clone https://huggingface.co/THUDM/chatglm-6b |
如果你从 Hugging Face Hub 上下载 checkpoint 的速度较慢,可以只下载模型实现
1 | GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6b |
然后从 这里 手动下载模型参数文件,并将下载的文件替换到本地的 chatglm-6b 目录下。
下载结束后,需要在 web_demo.py 或 cli_demo.py 中更新模型位置。
代码中默认从 THUDM/chatglm-6b 加载模型。
我们可以将目录移动过去:
1 | $ mkdir THUDM |
或是将代码中的 THUDM/chatglm-6b 替换为本地的 chatglm-6b 文件夹的路径。
GPU 加速
对于搭载了 Apple Silicon 的 Mac(以及 MacBook),可以使用 MPS 后端来在 GPU 上运行 ChatGLM-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly。
主要步骤如下:
1 | ## 拉取配置脚本 |
配置结束后修改 web_demo.py 或 cli_dmeo.py 中的这一行即可加速:
1 | -model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() |
调整模型加载方式
以上配置后运行会在模型加载报错,查阅资料需要修改一下模型仓库中的 THUDM/chatglm-6b/modeling_chatglm.py 这个文件,并做一下修改:
1 | diff --git a/modeling_chatglm.py b/modeling_chatglm.py |
注释了两行,暂时不清楚是什么含义,但注释之后就可以运行了,如果有知道的大神请指教。
运行
这里以 web_demo.py 为例,cli_dmeo.py 类比。
在 macOS 下我对该文件总共做了以下几处的修改:
1 | diff --git a/web_demo.py b/web_demo.py |
几处修改的目的分别如下:
- 解除内存限制,可能由于内存占用过高导致系统崩溃,如果不配置可能无法继续,我的 8G 运存很卡但暂时没有遇到崩溃,是否配置自行评估;
- 修改模型加载方式,用于调用 M1 芯片 GPU 加速;
- 开启共享链接,可以通过共享链接来访问,但不建议使用,速度很慢。不开启貌似会报错;
针对 cli_demo.py 只需要修改上面前两部分即可运行。
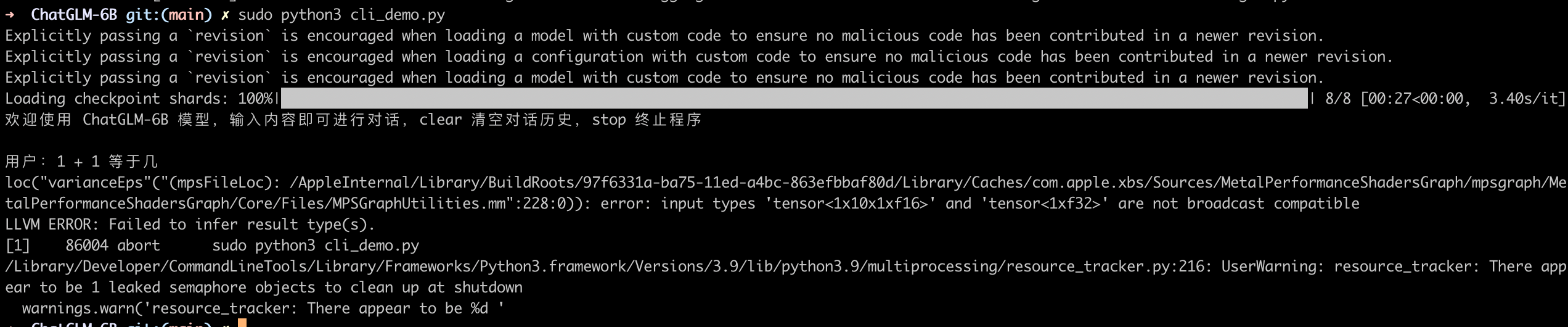
这样就可以运行起来了,web 版会自动弹出浏览器。
我这里由于资源实在有限,能加载已经很费力了,一旦对话就会强制退出。如果你的资源足够应该可以正常运行。
Linux noGPU 环境运行
手头没有 GPU 设备,在 Linux 环境下可以使用 CPU 的方式运行,会有比较高的内存和 CPU 占用。
环境准备 & 本地模型加载
环境准备和本地模型加载过程类似,这里就不赘述了。
类比 macOS 下的操作方法准备环境和本地仓库,之后继续。
CPU 运行
如果没有 GPU 硬件的话,可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
1 | model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float() |
如果你的内存不足,可以直接加载量化后的模型:
1 | model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4",trust_remote_code=True).float() |
运行
上面 CPU 运行部分的方法摘自官方 Git 的说明,下面贴出我对运行代码修改的部分:
1 | diff --git a/web_demo.py b/web_demo.py |
以上两处修改的目的如下:
- 使用纯 CPU 模式运行;
- 监听 0.0.0.0 用于外部访问。
这样就可以运行起来了。